엔비디아가 지포스 RTX 및 고성능 RTX 그래픽 카드의 텐서 코어를 이용해 AI 추론을 가속하는 윈도용 텐서RT-LLM을 공개했습니다.
윈도용 텐서RT-LLM은 앞서 데이터 센터용으로 공개한 바 있는 텐서RT-LLM 오픈 소스 라이브러리를 윈도 PC용으로 내놓은 것으로 지포스 RTX GPU에서 작동합니다.
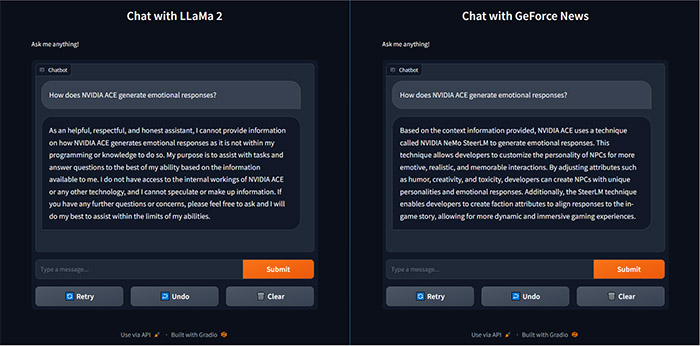
엔비디아는 텐서RT-LLM을 활용하면 메타의 라마2 및 코드 라마 같은 거대언어모델을 최대 4배 빠르게 실행할 수 있다고 밝혔습니다.
더불어 엔비디아는 텐서RT-LLM으로 커스텀 모델을 최적화하는 스크립트, 텐서RT에 최적화된 오픈 소스 모델, LLM 응답의 속도와 품질을 모두 보여주는 개발자 참조 프로젝트도 함께 공개했습니다.

텐서RT-LLM 도구 공개와 함께 엔비디아는 윈도 PC에서 실행되는 스테이블 디퓨전의 웹 UI인 Automatic1111용 텐서RT 가속 기능을 배포해 확산 속도를 2배 높였습니다.
유튜브, 프라임 비디오, 디즈니 플러스 등 스트리밍 영상에 적용해온 AI 화질 개선 기능인 RTX VSR에 아티팩트 제거 기능을 강화한 1.5 버전도 배포를 시작했습니다.
글쓴이 | Editor_B
언제나 기분 좋은 소식을 전하고 싶습니다.
news@techg.kr
언제나 기분 좋은 소식을 전하고 싶습니다.
news@techg.kr