
‘딥 러닝'(Deep Learning)은 인공 지능의 발전에 매우 중요한 부분이다. 인공지능이 무한한 양의 데이터를 이해할 수 있도록 학습하는 과정이 딥 러닝이기 때문이다. 그런데 딥 러닝 과정을 좀더 빨리 수행할 수 있도록 가속 페달의 역할을 하는 것이 다름 아닌 GPU다. 엔비디아 코리아가 10월 31일 개최한 GPU 중심의 인공지능 컨퍼런스를 딥 러닝 데이라 이름 지은 것은 이런 배경이 있다.
딥 러닝 데이라는 이름을 걸기 전에 사실 지난 해까지 GTCxKOREA라는 이름으로 개최되던 행사였다. 2015년과 2016년에 열린 GTCxKOREA까지 포함하면 이번 딥러닝데이는 3번째 인공지능 행사인 셈이다. 사실 GPU 테크놀로지 컨퍼런스의 약칭인 GTC는 보통 5월에 미국에서 열리는 단일 행사였으나 최근에는 세계 여러 곳을 돌며 그 이후의 성과를 공유하고 있다. 지난 한 달 동안 유럽과 이스라엘, 대만 등을 거쳤던 GTC는 워싱턴 DC에서 마무리할 예정이다. 다만 GTC라는 이름의 본 행사를 여는 지역이나 나라가 제한된 만큼 엔비디아 코리아는 인공지능 중심 컨퍼런스라는 점을 강조하는 의미로 딥 러닝 데이라 이름을 붙인 것이다.
 올해 딥 러닝 데이도 종전과 마찬 가지로 엔비디아의 GPU 기술은 물론 국내 GPU 기반 인공 지능 연구 성과를 공유했다. 딥 러닝과 헬스케어, AI 시티, 자율 주행, AI 스타트업, 로봇 등 세션에서 국내 학계와 기업, 스타트업이 연구하고 개발 중인 다채로운 인공 지능 관련 내용을 공개했는데, 지난 해보다 더 범위를 확대했을 뿐만 아니라 세션도 더 세분화됐다. 대부분 각 영역에 맞는 특수 목적으로 인공 지능을 발전시키고 있는 것은 마치 인공 지능을 사회 어디에서나 만나게 될 것이라는 점을 암시하는 것처럼…
올해 딥 러닝 데이도 종전과 마찬 가지로 엔비디아의 GPU 기술은 물론 국내 GPU 기반 인공 지능 연구 성과를 공유했다. 딥 러닝과 헬스케어, AI 시티, 자율 주행, AI 스타트업, 로봇 등 세션에서 국내 학계와 기업, 스타트업이 연구하고 개발 중인 다채로운 인공 지능 관련 내용을 공개했는데, 지난 해보다 더 범위를 확대했을 뿐만 아니라 세션도 더 세분화됐다. 대부분 각 영역에 맞는 특수 목적으로 인공 지능을 발전시키고 있는 것은 마치 인공 지능을 사회 어디에서나 만나게 될 것이라는 점을 암시하는 것처럼…
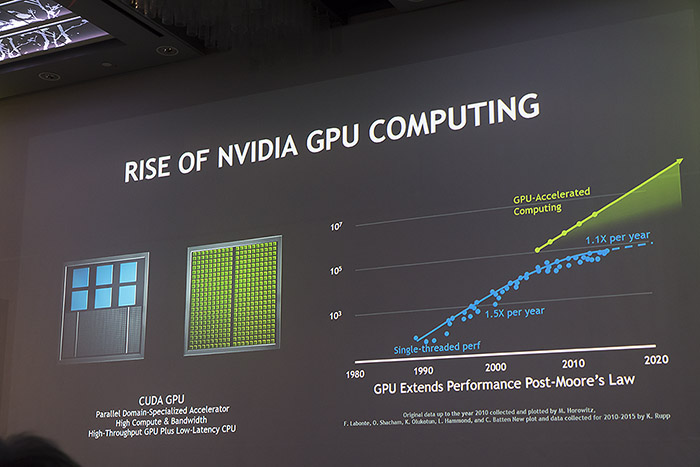
그런데 따지고 보면 사람이 해결하지 못하는 과학적 숙제를 풀거나 쉽게 판단을 내리기 어려운 문제의 해결을 돕는 오늘 날의 수준까지 오른 데 걸린 시간은 10여 년 밖에 되지 않는다. 인공 지능은 지난 10년 사이 급격히 발전했기 때문이다. 비록 반세기 전 인공 지능의 기초가 세워졌다고는 하나 더 강력해진 컴퓨팅 파워와 이를 학습하기 위한 데이터를 확보할 수 있는 클라우드 산업의 확산으로 가속했고, 인공 지능의 심화 학습 속도는 점점 더 빨라지고 있는 것이다.
 이 때 인공 지능을 위한 심화 학습의 가속 속도를 끌어 올린 것이 GPU라는 것은 이미 잘 알려진 사실이다. 100만 개의 이미지의 인식하고 추론하는 2012년의 이미지넷 테스트에서 처음으로 GPU를 활용한 심층 신경망 알렉스넷이 종전보다 10% 높은 85%의 인식률과 추론 속도를 향상한 것이 계기였다.
이 때 인공 지능을 위한 심화 학습의 가속 속도를 끌어 올린 것이 GPU라는 것은 이미 잘 알려진 사실이다. 100만 개의 이미지의 인식하고 추론하는 2012년의 이미지넷 테스트에서 처음으로 GPU를 활용한 심층 신경망 알렉스넷이 종전보다 10% 높은 85%의 인식률과 추론 속도를 향상한 것이 계기였다.
이후 엔비디아는 인공 지능의 심화 학습 성능을 올리는 GPU 아키텍처를 개선하고 이를 활용하기 위해 만든 하드웨어 및 소프트웨어 플랫폼을 구축한 성과를 공개했다. 특히 알렉스넷에서 85%의 성과를 보였던 이미지 인식률은 이미 초인간적인 인식률을 보이기 시작했고, 2016년에 등장한 또 다른 심화 신경망인 인셉션 V4는 알렉스넷에 비해 350배의 컴퓨팅 파워로 인식률과 속도를 더욱 끌어 올리는 데도 힘을 보냈다. 음성을 인식하는 딥스피치 3는 30배, 인공 지능 기반 번역 플랫폼인 MoE는 오픈NMT에 비해 10배 이상 성능이 나아졌다.
 이러한 결과는 카페2와 텐서 플로 등 인공 지능을 위한 모든 프레임 워크를 지원하고 인공 지능 스타트업을 지원할 뿐만 아니라 아마존 웹서비스, 알이바바 클라우드, 구글 클라우드 플랫폼, 마이크로소프트 애저 등 수많은 클라우드에 엔비디아 테슬라와 볼타 아키텍처에 기반한 시스템을 구축해 얻은 것이다. 여기에 개발자들이 좀더 쉽게 인공 지능 도구를 이용할 수 있도록 엔비디아 GPU 클라우드도 선보였다. 여러 개의 GPU를 써야 할 때 멀티 노드를 위한 소프트웨어 설정 시간을 줄이도록 모든 설정을 한번에 끝낼 수 있고, 이를 이용해 수천 개의 소프트웨어를 GPU로 손쉽게 가속화할 수 있다.
이러한 결과는 카페2와 텐서 플로 등 인공 지능을 위한 모든 프레임 워크를 지원하고 인공 지능 스타트업을 지원할 뿐만 아니라 아마존 웹서비스, 알이바바 클라우드, 구글 클라우드 플랫폼, 마이크로소프트 애저 등 수많은 클라우드에 엔비디아 테슬라와 볼타 아키텍처에 기반한 시스템을 구축해 얻은 것이다. 여기에 개발자들이 좀더 쉽게 인공 지능 도구를 이용할 수 있도록 엔비디아 GPU 클라우드도 선보였다. 여러 개의 GPU를 써야 할 때 멀티 노드를 위한 소프트웨어 설정 시간을 줄이도록 모든 설정을 한번에 끝낼 수 있고, 이를 이용해 수천 개의 소프트웨어를 GPU로 손쉽게 가속화할 수 있다.
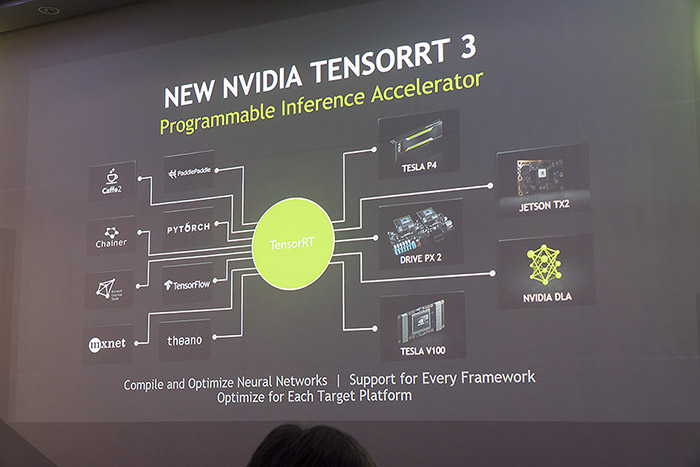 하지만 엔비디아는 하드웨어가 인공 지능 가속을 위해 모든 것을 해결해 주진 않을 것이라고 진단한 듯하다. 이미 2천만 대에 이르는 서버들이 추론에 활용되고 있고 많은 전력과 비용을 소모하고 있음을 목격했기 때문이다. 이러한 자원 소비는 앞으로 더 증가할 것이므로 다른 대책을 찾아야 했고, 소프트웨어의 효율에서 대책을 찾기로 했다. 그것이 텐서RT다. 텐서 RT는 프로그래밍 할 수 있는 추론 가속기다. 카페2나 텐서플로 같은 온갖 프레임워크의 각종 그래프를 자르고 붙여 최적화한 뒤 추론 그래프로 실시간으로 변환한다. 실제로 마이크로소프트의 레스넷 이미지 추론에 텐서 RT를 활용한 결과 텐서플로 프레임워크에서 140개의 이미지를 처리하던 시스템에서 40배 향상된 5천700개를 처리할 수 있었다고. 결국 처리 속도를 높이면 그만큼 처리해야 할 서버의 수를 줄여 비용을 낮출 수 있다는 것이다.
하지만 엔비디아는 하드웨어가 인공 지능 가속을 위해 모든 것을 해결해 주진 않을 것이라고 진단한 듯하다. 이미 2천만 대에 이르는 서버들이 추론에 활용되고 있고 많은 전력과 비용을 소모하고 있음을 목격했기 때문이다. 이러한 자원 소비는 앞으로 더 증가할 것이므로 다른 대책을 찾아야 했고, 소프트웨어의 효율에서 대책을 찾기로 했다. 그것이 텐서RT다. 텐서 RT는 프로그래밍 할 수 있는 추론 가속기다. 카페2나 텐서플로 같은 온갖 프레임워크의 각종 그래프를 자르고 붙여 최적화한 뒤 추론 그래프로 실시간으로 변환한다. 실제로 마이크로소프트의 레스넷 이미지 추론에 텐서 RT를 활용한 결과 텐서플로 프레임워크에서 140개의 이미지를 처리하던 시스템에서 40배 향상된 5천700개를 처리할 수 있었다고. 결국 처리 속도를 높이면 그만큼 처리해야 할 서버의 수를 줄여 비용을 낮출 수 있다는 것이다.
 그런데 지금까지 인공 지능은 클라우드와 연동해 작동하고 있는 상황이다. 네트워크를 통해 장치의 데이터를 클라우드로 보낸 뒤 그 결과를 장치에서 받아보는 것이다. 아주 빠른 네트워크와 뛰어난 처리 능력을 갖고 있어도 데이터를 주고받으며 처리하는 시간을 고려하면 적지 않은 지연이 생긴다. 엔비디아가 센서나 카메라를 통해 수신된 데이터를 장치의 인공 지능이 직접 처리하는 엣지 컴퓨팅에 눈을 돌리는 이유가 이 때문이다. 자율 주행 자동차나 자율 주행 드론, 배송 로봇 등 현장 상황에 맞춰 판단하는 것이 더 중요하기 때문이다.
그런데 지금까지 인공 지능은 클라우드와 연동해 작동하고 있는 상황이다. 네트워크를 통해 장치의 데이터를 클라우드로 보낸 뒤 그 결과를 장치에서 받아보는 것이다. 아주 빠른 네트워크와 뛰어난 처리 능력을 갖고 있어도 데이터를 주고받으며 처리하는 시간을 고려하면 적지 않은 지연이 생긴다. 엔비디아가 센서나 카메라를 통해 수신된 데이터를 장치의 인공 지능이 직접 처리하는 엣지 컴퓨팅에 눈을 돌리는 이유가 이 때문이다. 자율 주행 자동차나 자율 주행 드론, 배송 로봇 등 현장 상황에 맞춰 판단하는 것이 더 중요하기 때문이다.
다만 엔비디아는 모든 영역에서 엣지 컴퓨팅을 실현하려는 게 아닌 듯하다. 자율 주행 자동차나 드론을 포함해 스스로 움직이는 로봇처럼 자율적인 판단을 해야 하는 분야에 관심이 높아 보인다. 이미 자율 주행 자동차 분야에서 엔비디아는 전용 컴퓨터를 여러 차례 내놨고, 로봇택시를 위한 자동차 번호판 크기의 페가수스라는 자율 주행 컴퓨터를 GTC 유럽에서 발표하기도 했다. 또한 자율 주행 자동차의 완성을 높이기 위한 시뮬레이터도 공개했는데, 이를 활용하면 실제 도로를 달리지 않도 110억 마일의 자율 주행 훈련 데이터를 얻을 수 있다. 자율 주행 레벨 4 자동차도 내년이면 상용화될 예정이어서 자율 주행 자동차 시대를 더 일찍 만나게 될 듯하다.
 자율 주행 자동차에 비해 완전 자율 판단 로봇은 더 어려운 영역이다. 공장에서 프로그래밍된 로봇이 어려운 작업을 수행하고 있지만, 스스로 판단하고 움직이기 위한 학습이 필요해서다. 문제는 로봇 시제품으로 모든 학습을 하는 것은 시간이 너무 오래 걸린다는 점이다. 때문에 로봇의 인공 지능을 위해 홀로데크에 실제 로봇처럼 움직이는 로봇 시뮬레이터를 다수 배치한 뒤 각 시뮬레이션하는 로봇마다 주어진 문제를 풀도록 해 심화 학습을 가속하는 방법도 도입했다. 아직 이를 이용한 결과는 나오지 않았지만, 공장 뿐만 아니라 의료나 배송 등 일상에서 다양한 형태로 존재하게 될 로봇의 인공 지능이 얼마나 빨리 성장할 것인지 지켜봐야 할 듯하다.
자율 주행 자동차에 비해 완전 자율 판단 로봇은 더 어려운 영역이다. 공장에서 프로그래밍된 로봇이 어려운 작업을 수행하고 있지만, 스스로 판단하고 움직이기 위한 학습이 필요해서다. 문제는 로봇 시제품으로 모든 학습을 하는 것은 시간이 너무 오래 걸린다는 점이다. 때문에 로봇의 인공 지능을 위해 홀로데크에 실제 로봇처럼 움직이는 로봇 시뮬레이터를 다수 배치한 뒤 각 시뮬레이션하는 로봇마다 주어진 문제를 풀도록 해 심화 학습을 가속하는 방법도 도입했다. 아직 이를 이용한 결과는 나오지 않았지만, 공장 뿐만 아니라 의료나 배송 등 일상에서 다양한 형태로 존재하게 될 로봇의 인공 지능이 얼마나 빨리 성장할 것인지 지켜봐야 할 듯하다.
 이 밖에도 AI 도시 같은 설명이나 몇몇 엔비디아 하드웨어 제품들에 대한 소개도 이어졌지만, 엔비디아 샹커 드리베디 수석 부사장이 딥 러닝 데이 2017에서 공유한 올해의 성과들은 이것 만으로도 모자랄 것 같지는 않다. 올해 노벨 화학상과 물리학상도 GPU의 기여도가 높았다는 점은 말하지 않더라도 인공 지능 분야의 발전에 필요한 기술과 제품을 확대해가는 것을 멈추지 않았다는 것을 확인하는 것은 어렵지 않아서다. 아마도 워싱턴 DC에서 열리는 GTC DC에서 또 다른 성과들이 발표될 수도 있는데, 모든 것이 인공 지능 분야에서 새로운 길을 내는 것이나 다름 없다.
이 밖에도 AI 도시 같은 설명이나 몇몇 엔비디아 하드웨어 제품들에 대한 소개도 이어졌지만, 엔비디아 샹커 드리베디 수석 부사장이 딥 러닝 데이 2017에서 공유한 올해의 성과들은 이것 만으로도 모자랄 것 같지는 않다. 올해 노벨 화학상과 물리학상도 GPU의 기여도가 높았다는 점은 말하지 않더라도 인공 지능 분야의 발전에 필요한 기술과 제품을 확대해가는 것을 멈추지 않았다는 것을 확인하는 것은 어렵지 않아서다. 아마도 워싱턴 DC에서 열리는 GTC DC에서 또 다른 성과들이 발표될 수도 있는데, 모든 것이 인공 지능 분야에서 새로운 길을 내는 것이나 다름 없다.
하지만 늘 그렇 듯이 인공 지능의 이 같은 성과들이 실제 우리 삶에 어떻게 영향을 미치는지 그것을 분석해야 할 시간도 점점 다가오고 있다. 그것 만큼은 인공 지능이 아니라 사람이 직접 생각하고 판단해야 할 일이 아닐까…?
직접 보고 듣고 써보고 즐겼던 경험을 이야기하겠습니다.
chitsol@techg.kr






