인공 지능 기술이 빠르게 발전하면서 인공 지능의 능력을 향상시킬 수 있는 GPU 기술에 관심이 높아진 것이 사실입니다. 하지만 지난 해 구글이 공개했던 TPU(텐서 프로세서 유닛)은 인공 지능의 추론 능력을 가속할 수 있는 결과가 공개되면서 GPU 이외의 인공 지능 전용 프로세서의 등장을 떠들썩하게 반기기도 했죠.
인공 지능 기술이 빠르게 발전하면서 인공 지능의 능력을 향상시킬 수 있는 GPU 기술에 관심이 높아진 것이 사실입니다. 하지만 지난 해 구글이 공개했던 TPU(텐서 프로세서 유닛)은 인공 지능의 추론 능력을 가속할 수 있는 결과가 공개되면서 GPU 이외의 인공 지능 전용 프로세서의 등장을 떠들썩하게 반기기도 했죠.
이에 GPU 기반 인공 지능 기술을 다듬어 온 엔비디아가 새 답을 들고 나타났습니다. 엔비디아는 산호세에서 열리고 있는 GPU 기술 컨퍼런스(GPU Tech Conference)에서 텐서 코어를 추가한 볼타 아키텍처와 관련 제품을 대거 공개했는데요. 새로운 볼타 아키텍처를 내놓기 위해 엔비디아는 30억 달러를 투입했다고 하는군요.
볼타 아키텍처를 적용한 GPU인 GV100은 GPU를 활용한 프로그램을 처리하기 위한 5,120개의 쿠다 코어와 함께 672개의 텐서 코어를 처음으로 다이에 실장, 인공 지능의 심화 학습과 추론을 모두 가속할 수 있는 범용 GPU로 등장했습니다. 새로운 코어와 추가된 CUDA 코어, 캐시 증가 등 2,121억 개의 트랜지스터를 집적하고 있어 12nm 공정으로 생산함에도 다이 크기는 파스칼 아키텍처 기반 GP100보다 33% 더 커졌습니다.
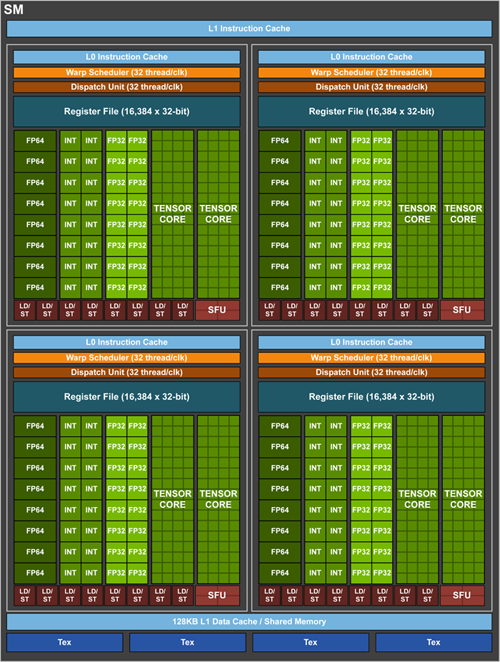 텐서 코어는 FP16의 4X4 행렬 연산을 수행하는 것으로, 하나의 유닛에서 거대한 행렬-행렬 곱셈을 처리함으로써 초당 부동소수점 처리(FLOPS) 효율을 높입니다.
텐서 코어는 FP16의 4X4 행렬 연산을 수행하는 것으로, 하나의 유닛에서 거대한 행렬-행렬 곱셈을 처리함으로써 초당 부동소수점 처리(FLOPS) 효율을 높입니다.
단일 텐서 코어는 클럭당 128FLOPS를 처리하는데요. SM(Streaming Multiprocessor)당 8개의 텐서 코어가 있어 SM 클럭 당 1024 FLOPS를 수행합니다. 종전 텐서 코어가 없는 파스칼의 CUDA 코어를 이용해 행렬을 계산할 때 256FLOPS에 비하면 4배 더 향상됐고, 추론 속도는 6배 빨라졌습니다. 엔비디아는 텐서 플로(Tensorflow) 및 Caffe 용 컴파일러 TensorRT(텐서 런타임)도 공개해 GPU에서 런타임 성능을 최적화했습니다.
엔비디아는 데이터 센터를 위해 NV링크 및 PCIe 용테슬라 V100을 공개했을 뿐만 아니라, 6대의 볼타 GPU를 탑재한 새로운 DGX-1(14만9천 달러)과 독립형 AI 컴퓨터인 엔비디아 DGX 스테이션(NVIDIA DGX Station)도 함께 소개했습니다.
 특히 책상 아래 넣을 수 있는 데스크톱 컴퓨터 크기의 엔비디아 DGX 스테이션(6만9천 달러)은 4대의 V100 GPU를 넣어 480TFLOPS의 텐서 컴퓨팅 파워를 낼 수 있으며, 수냉식이어서 매우 조용히 작동합니다.
특히 책상 아래 넣을 수 있는 데스크톱 컴퓨터 크기의 엔비디아 DGX 스테이션(6만9천 달러)은 4대의 V100 GPU를 넣어 480TFLOPS의 텐서 컴퓨팅 파워를 낼 수 있으며, 수냉식이어서 매우 조용히 작동합니다.
볼타 아키텍처 기반 GPU와 제품 이외에도 엔비디아는 GTC에서 인공 지능을 활용한 기술과 제품을 대거 공개했습니다. 자세한 내용은 GTC 웹사이트에서 확인할 수 있습니다.
언제나 기분 좋은 소식을 전하고 싶습니다.
news@techg.kr