하나의 CPU에 최대 72개의 코어를 담고 있다면 왠지 욕심날 지도 모르겠다. 하지만 이 CPU는 개인용 데스크톱 컴퓨터나 노트북에서 쓰기 위한 용도로 만든 게 아니다. 대규모 서비스에 필요한 서버나 복잡한 계산 또는 인공 지능을 위한 기계 학습을 위한 고성능 컴퓨팅(High Performance Computing)을 위해서 만든 프로세서다. 인텔 제온 파이(Intel Xeon Phi)의 이야기다.
고성능 컴퓨팅용 프로세서, 제온 파이는 다수의 코어를 내장한 병렬 프로세서다. 프로그램에서 지시하는 명령에 따라 순차적으로 데이터를 처리하는 프로세서와 달리 수많은 코어가 각각 주어진 역할을 맡아 데이터를 계산한다. 물론 제온 파이의 각 코어는 아톰 프로세서에서 볼 수 있는 실버몬트 기반이라 프로그램의 실행이 어렵지는 않지만, 프로세서의 쓰임새가 다르고 부분적으로 구성에도 변화를 뒀다. 무엇보다 병렬 컴퓨팅은 수치 계산에 유리한 터라 이에 대한 대응은 매우 중요하다. 종전에는 정부 기관이나 과학적 분석을 많이 하는 곳에서 썼지만, 지금은 클라우드와 인공 지능을 개발하는 기업에서 널리 쓰이고 있기 때문이다. 특히 어떤 가설을 입증하기 위해서 고성능 컴퓨팅을 이용하고 결과를 받았던 예전과 달리, 계산된 결과를 기계에서 직접 학습하고 판단과 행동을 결정하는 기계 학습 시대에 유연하게 대응할 수 있는 프로세서의 수요는 점점 높아지고 있고, 인텔은 6년 전부터 제온 파이를 통해 대응을 준비해왔다.
 지난 6월 22일 국제 슈퍼컴퓨터 학회(International Supercomputer Confrence)에서 인텔은 4세대 인텔 제온 파이를 공개했다. 이 행사에 앞서 미리 협력사들에게 공급하고 있던 인텔 제온 파이 프로세서가 벌써 4세대까지 이른 것이다. 코드명은 나이츠 랜딩(Knights Landing). 그런데 4세대는 지난 세대와 조금 다른 점이 있다. 이 프로세서가 이제야 단독으로 작동하는 프로세서가 됐다는 점이다.
지난 6월 22일 국제 슈퍼컴퓨터 학회(International Supercomputer Confrence)에서 인텔은 4세대 인텔 제온 파이를 공개했다. 이 행사에 앞서 미리 협력사들에게 공급하고 있던 인텔 제온 파이 프로세서가 벌써 4세대까지 이른 것이다. 코드명은 나이츠 랜딩(Knights Landing). 그런데 4세대는 지난 세대와 조금 다른 점이 있다. 이 프로세서가 이제야 단독으로 작동하는 프로세서가 됐다는 점이다.
앞서 나왔던 제온 파이는 PCI 익스프레스 3.0 슬롯에 꽂는 보조 프로세서(co-processor)였다. 고성능 컴퓨팅을 위한 CPU의 부족한 연산 능력을 보완하기 위한 만들었던 터라 반드시 제온 프로세서가 있는 장비에 꽂아야 작동했던 것. 그런데 4세대는 따로 CPU를 쓰지 않아도 된다. 4세대 제온 파이 안에 시스템 시작에 필요한 프로세서를 모두 포함하고 있기 때문이다. 이제는 보조 프로세서가 아니라 호스트 운영체제를 실행할 수 있는 프로세서라고 부를 수 있게 됐다.
 자체 부팅을 한다는 것은 두 가지 의미를 더 담고 있다. 일단 PCI 익스프레스 슬롯을 쓰지 않고 소켓에 꽂은 채로 부팅을 하기 때문에 PCI 익스프레스 슬롯을 쓸 때 생길 수밖에 없는 병목 현상을 고민하지 않아도 된다. 충분하지 못한 PCI 익스프레스의 대역폭 문제에서 벗어나 병목 현상을 해결한 만큼 처리 효율성도 그만큼 높아진다. 더불어 인텔 아키텍처를 기반으로 작동하기 때문에 종전 제온에서 운용하던 소프트웨어도 그대로 호환된다. 이전 세대 제온 파이처럼 다시 컴파일하지 않고 그대로 쓸 수 있을 만큼 명령어 세트를 갖고 있다.
자체 부팅을 한다는 것은 두 가지 의미를 더 담고 있다. 일단 PCI 익스프레스 슬롯을 쓰지 않고 소켓에 꽂은 채로 부팅을 하기 때문에 PCI 익스프레스 슬롯을 쓸 때 생길 수밖에 없는 병목 현상을 고민하지 않아도 된다. 충분하지 못한 PCI 익스프레스의 대역폭 문제에서 벗어나 병목 현상을 해결한 만큼 처리 효율성도 그만큼 높아진다. 더불어 인텔 아키텍처를 기반으로 작동하기 때문에 종전 제온에서 운용하던 소프트웨어도 그대로 호환된다. 이전 세대 제온 파이처럼 다시 컴파일하지 않고 그대로 쓸 수 있을 만큼 명령어 세트를 갖고 있다.
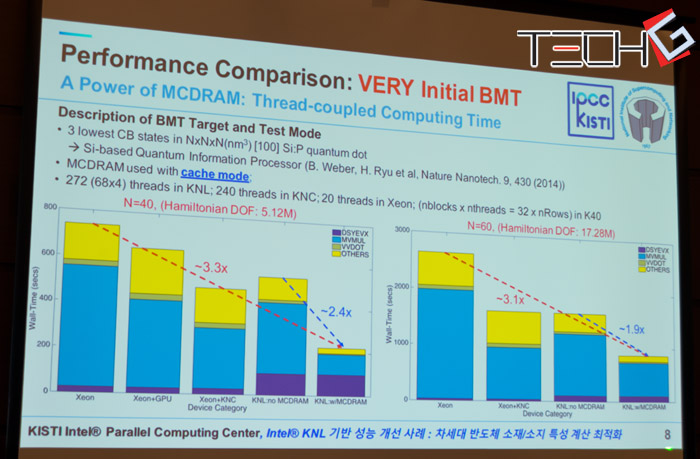
PCI 슬롯의 병목 현상에서 해방된 제온 파이는 고성능 컴퓨팅 시장의 요구에 대응하기 위한 성능과 확장의 유연성도 보강했다. 일단 최대 384GB의 DDR4램을 6채널로 연결해 쓸 수 있으면서도 좀더 효율적인 처리를 위해 대역폭이 높은 16GB의 MCDRAM을 프로세서 안에 통합했다. 캐시 모드나 플랫 모드로 쓸 수 있는 MCDRAM을 통합한 것과 하지 않은 것의 성능 차이는 매우 크다. 272 스레드를 처리하는 4세대 제온 파이와 240 스레드의 3세대 제온 파이+20스레드의 제온 프로세서의 처리 시간을 비교했을 때 MCDRAM의 유무에 따라 2배 가까운 처리 시간의 차이를 보인다. 또한 병렬 처리를 위해 프로세스간 정보를 교환하는 MPI 성능(MPI Performance)도 MCDRAM의 작동 여하에 따라 12배까지 달라진다.
 인텔은 고성능 컴퓨팅 환경을 구축하는 데 필요한 프로세서와 저장 장치, 메모리, 스위치 등 각 구성 요소를 독립된 모듈 형태로 연결, 유연하게 확장할 수 있는 패브릭 컴퓨팅에 대응할 수 있도록 고성능 인터커넥트 기술인 인텔 옴니 패스 아키텍처를 결합한 제온 파이 프로세서도 따로 내놓는다. 포트당 25GB/s의 대역폭을 가진 인텔 옴니 패스 아키텍처를 통합한 제온 파이는 2포트 옴니 패스 커넥터를 내장했고, PCI 익스프레스 슬롯을 통해 외부와 연결된다. 하지만 앞으로는 PCI 익스프레스 슬롯을 거치지 않고 프로세서 소켓에서 직접 연결되는 형태가 될 것으로 알려졌다. 인텔은 패브릭을 위한 8만 여개 이상의 노드를 이미 확보했고 델과 후지쯔, HP, 레노버, 오라클 등 주요 시스템 제조 업체들이 옴니패스 아키텍처 기반 스위치와 서버 플랫폼을 출하 중이라고 밝혔다.
인텔은 고성능 컴퓨팅 환경을 구축하는 데 필요한 프로세서와 저장 장치, 메모리, 스위치 등 각 구성 요소를 독립된 모듈 형태로 연결, 유연하게 확장할 수 있는 패브릭 컴퓨팅에 대응할 수 있도록 고성능 인터커넥트 기술인 인텔 옴니 패스 아키텍처를 결합한 제온 파이 프로세서도 따로 내놓는다. 포트당 25GB/s의 대역폭을 가진 인텔 옴니 패스 아키텍처를 통합한 제온 파이는 2포트 옴니 패스 커넥터를 내장했고, PCI 익스프레스 슬롯을 통해 외부와 연결된다. 하지만 앞으로는 PCI 익스프레스 슬롯을 거치지 않고 프로세서 소켓에서 직접 연결되는 형태가 될 것으로 알려졌다. 인텔은 패브릭을 위한 8만 여개 이상의 노드를 이미 확보했고 델과 후지쯔, HP, 레노버, 오라클 등 주요 시스템 제조 업체들이 옴니패스 아키텍처 기반 스위치와 서버 플랫폼을 출하 중이라고 밝혔다.
이처럼 인텔은 고성능 병렬 컴퓨팅을 위한 여러 조건을 채운 4세대 제온 파이가 인공 지능과 관련된 영역에서 좀더 역할을 맡을 수 있도록 기계 학습 오픈소스 커뮤니티에 대한 활동을 강화한다. 카페(Caffe), 텐서플로(TensorFlow) 같은 딥러닝 프레임워크에 최적화할 뿐만 아니라 심층신경망(Deep Neuron Network)를 위한 MKL(Math Kernel Libraries)도 최적화해 내놓을 계획이다. 고성능 컴퓨팅 환경에서 애플리케이션 최적화를 위한 행사는 국내에서도 진행된다. 제온 파이 기반에서 개발 제품을 최적화하는 방법에 대해 교육하는 CMEP(Code Modernization Enablement)를 통해 지금까지 600명의 개발자가 교육을 받았고, 하반기 400명을 추가해 올해 1천명에게 관련 지식을 전수하려는 목표를 갖고 있다.
 인텔 제온 파이는 모두 4가지 모델로 출시된다. 72개 코어로 노드당 성능을 강조하는 제온 파이 7290과 와트당 성능이 좋은 68코어의 7250, 코어당 메모리 대역폭의 균형을 잡은 64코어의 7230, 그리고 가격이 좋은 64코어의 7210 등이다. 이 프로세서는 이미 출시 중으로 국내에 도입 되고 있다. 한국과학기술정보연구원(KISTI)가 인텔과 파트너십을 맺고 현재 차세대 반도체 소재 특성 모델링 연산을 위해 새로운 제온 파이를 이용하고 있다.
인텔 제온 파이는 모두 4가지 모델로 출시된다. 72개 코어로 노드당 성능을 강조하는 제온 파이 7290과 와트당 성능이 좋은 68코어의 7250, 코어당 메모리 대역폭의 균형을 잡은 64코어의 7230, 그리고 가격이 좋은 64코어의 7210 등이다. 이 프로세서는 이미 출시 중으로 국내에 도입 되고 있다. 한국과학기술정보연구원(KISTI)가 인텔과 파트너십을 맺고 현재 차세대 반도체 소재 특성 모델링 연산을 위해 새로운 제온 파이를 이용하고 있다.
직접 보고 듣고 써보고 즐겼던 경험을 이야기하겠습니다.
chitsol@techg.kr