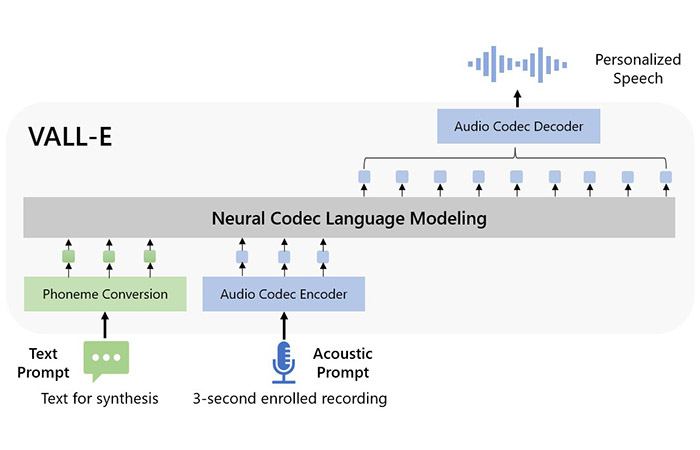
마이크로소프트 연구원들이 3초의 음성 샘플만 듣고 유사한 사람 목소리를 합성할 수 있는 VALL-E에 대한 논문을 깃허브에 공개했습니다.
VALL-E는 문자를 음성으로 변환하는 기존의 TTS(Text To Speech)를 위한 모델링이지만, 일상적인 말처럼 자연스럽게 말할 수 있습니다.
연구진들은 6만 시간의 영어 음성으로 사전 훈련을 진행했고, 실험 결과 문장을 읽는 음성의 자연스러운과 화자의 유사성에서 성능이 뛰어나다고 밝혔습니다.
특히 단순한 문장을 기계적 언어로 자연스럽게 읽어주는 수준을 넘어 감정에 따라 표현을 바꿀 수 있습니다.
다만 연구진들은 음성 합성에 관한 코드는 제공하지 않았는데, 음성 합성으로 인한 잠재적인 사회적 피해를 막기 위한 것으로 보입니다.
글쓴이 | Editor_B
언제나 기분 좋은 소식을 전하고 싶습니다.
news@techg.kr
언제나 기분 좋은 소식을 전하고 싶습니다.
news@techg.kr